
Faits saillants
- Robots.txt est un outil puissant pour gérer le comportement des moteurs de recherche sur les sites Web.
- Robots.txt Interdire tout empêche tous les moteurs de recherche d’explorer votre site.
- Une utilisation incorrecte de robots.txt peut nuire au référencement et ralentir la réindexation après les modifications.
- Pour la sécurité ou le contenu privé, utilisez une protection par mot de passe au lieu de vous fier à la directive Disallow.
- Un audit régulier robots.txt fichier permet de s’assurer qu’il est optimisé pour la visibilité des moteurs de recherche.
Introduction
Une marque de commerce électronique bien connue s’est déjà retrouvée dans un cauchemar SEO. Du jour au lendemain, ses pages ont disparu des résultats de recherche Google, entraînant une baisse soudaine du trafic organique et des revenus.
Après des heures de dépannage frénétique, le coupable a été découvert : un robots.txt égaré Interdire tout. Cette seule ligne avait effectivement empêché les moteurs de recherche d’explorer l’ensemble du site, le rendant invisible pour les clients potentiels.
La directive robots.txt Disallow all est un outil puissant. Mais lorsqu’il est mal utilisé, il peut saboter votre classement de recherche, ralentir la réindexation et causer des dommages importants au référencement.
Alors, que fait exactement Disallow all ? Quand faut-il l’utiliser ou l’éviter ? Dans cet article, nous allons tout explorer sur robots.txt Tout interdire.
Qu’est-ce qu’un fichier robots.txt ?
Un fichier robots.txt est un fichier texte brut situé dans le répertoire du domaine racine de votre site Web. Il décide quels robots des moteurs de recherche y pénètrent et quelles zones ils sont autorisés à explorer ou à enregistrer. Ce fichier suit le protocole d’exclusion des robots, également connu sous le nom de Robots Exclusion Standard. Il s’agit d’un ensemble de directives que les différents moteurs de recherche suivent lorsqu’ils explorent des sites Web.
Sans un fichier robots.txt bien configuré, les robots de Google peuvent se déplacer librement, indexant tout. Il peut s’agir de pages que vous ne souhaitez pas voir apparaître dans les résultats de recherche, telles que des pages d’administration, du contenu dupliqué ou des environnements de test.
Note: Google impose une limite de taille de 500 Kio pour les fichiers robots.txt. Tout contenu dépassant la taille maximale du fichier est ignoré.
Vous pouvez créer et modifier votre fichier robots.txt à l’aide du plugin Yoast SEO ou des fichiers du serveur de votre site Web. Google Search Console offre également des informations utiles pour gérer facilement robots.txt fichier.
Lisez aussi : Comment exclure Google de l’indexation Ajouter à la page WordPress du panier à l’aide de Yoast SEO
Exemples de fonctionnement des fichiers robots.txt
Robots.txt a des règles différentes en fonction de l’accès que vous souhaitez accorder aux robots des moteurs de recherche. Voici quelques exemples courants :
Exemple 1 : Autoriser tous les bots à accéder à l’ensemble du site web
User-agent: *
Disallow:Ce qu’il fait :
- Le ‘User-agent : *’ signifie que tous les robots des moteurs de recherche (Googlebot, Bingbot, etc.) peuvent accéder au site.
- Le champ « Vide interdit » signifie qu’il n’y a aucune restriction et que les robots peuvent tout explorer.
Quand l’utiliser : Si vous voulez une visibilité complète sur les moteurs de recherche pour l’ensemble de votre site Web.
Exemple 2 : Interdire à tous les bots d’accéder à un répertoire spécifique
User-agent: *
Disallow: /private-directory/Ce qu’il fait : Empêche tous les robots des moteurs de recherche d’accéder à tout ce qui se trouve à l’intérieur de ‘/private-directory/’.
Quand l’utiliser : Si vous souhaitez masquer des zones sensibles telles que les panneaux d’administration ou les données confidentielles.
Exemple 3 : Autoriser Googlebot tout en interdisant à d’autres personnes d’un annuaire
User-agent: Googlebot
Disallow: /images/
User-agent: *
Disallow: /private-directory/Ce qu’il fait :
- Googlebot ne peut pas accéder au répertoire /images/.
- Tous les autres bots ne peuvent pas accéder à /private-directory/.
Quand l’utiliser : Si vous souhaitez contrôler l’accès de robots spécifiques, par exemple en laissant Google explorer certaines parties de votre site tout en en bloquant d’autres.
Exemple 4 : Spécifier l’emplacement de votre Sitemap XML
User-agent: *
Disallow:
Sitemap: https://www.[yourwebsitename].com/sitemap.xmlCe qu’il fait :
- Permet un accès complet aux robots des moteurs de recherche.
- Indique aux moteurs de recherche où trouver le sitemap XML, ce qui les aide à indexer efficacement les pages.
Quand l’utiliser : Si vous souhaitez que les moteurs de recherche trouvent et explorent facilement votre sitemap.
A lire aussi : Comment créer un sitemap WordPress
Différence entre robots.txt vs. méta-robots vs. X-Robots-Tag
Bien que les robots.txt, les méta-robots et les X-robots contrôlent la façon dont les moteurs de recherche interagissent avec votre contenu, ils ont des objectifs différents.
- Robots.txt : Empêche l’exploration, mais les pages peuvent toujours apparaître dans les résultats de recherche si elles sont liées ailleurs.
- Balise Meta robots : Influence directement l’indexation et l’exploration des pages individuelles.
- X-Robots-Tag : Contrôle l’indexation des fichiers non HTML tels que les PDF, les images et les vidéos.
| Caractéristique | Robots.txt | Balises Meta robots | X-Robots-Tag |
| Emplacement | Répertoire racine (/robots.txt) | section d’une page web | Réponse d’en-tête HTTP |
| Contrôles | Des sections entières d’un site | Indexation et exploration de pages spécifiques | Indexation de fichiers non-HTML |
| Exemple | Interdire : /private/ | X-Robots-Tag : noindex | |
| Impact sur le référencement | Empêche les bots d’explorer, mais n’empêche pas l’indexation s’ils sont liés ailleurs | Empêche l’indexation et l’affichage d’une page dans les résultats de recherche | Garantit que les fichiers non HTML ne sont pas indexés |
| Meilleur cas d’utilisation | Bloquer les moteurs de recherche d’annuaires entiers | Empêcher l’affichage de pages spécifiques dans les résultats de recherche | Contrôlez l’indexation des PDF, des images et d’autres fichiers |
6 Syntaxe robots.txt courante
Comprendre robots.txt est plus facile lorsque vous connaissez ses règles de base. Ces règles simples permettent de gérer le fonctionnement des robots des moteurs de recherche avec votre site web :
- Agent utilisateur : Cette règle indique à quel bot ou robot d’indexation les instructions suivantes sont destinées.
- Interdire: Cette règle indique aux robots de ne pas visiter de fichiers, de dossiers ou de pages spécifiques de votre site qui peuvent inclure certaines expressions régulières.
- Permettre: Cette règle permet aux bots d’explorer certains fichiers, dossiers ou pages.
- Plan du site : Cette règle dirige les moteurs de recherche vers l’emplacement du sitemap XML de votre site Web.
- Délai de crawl : Cette règle demande aux bots d’explorer votre site plus lentement. Mais tous les moteurs de recherche ne suivent pas cette règle.
- Noindex : Cette règle demande aux robots de ne pas indexer certaines pages ou parties de votre site. Pourtant, la prise en charge par Google de la règle noindex dans robots.txt est incohérente.
1. Directive sur l’agent utilisateur
La règle ‘User-agent’ est importante pour votre fichier robots.txt. Il indique à quel bot ou crawler les règles s’appliquent. Chaque moteur de recherche a un nom unique appelé « agent utilisateur ». Par exemple, le robot d’indexation de Google s’appelle lui-même « Googlebot ».
Si vous souhaitez cibler uniquement Googlebot, écrivez :
User-agent: GooglebotVous pouvez taper différents agents utilisateurs séparément, chacun avec ses propres règles. Vous pouvez également utiliser le caractère générique ‘*’ pour que les règles s’appliquent à tous les agents utilisateurs.
2. Interdire robots.txt directive
La règle « Interdire » est très importante pour décider quelles parties de votre site Web doivent être cachées aux moteurs de recherche. Cette règle indique aux robots des moteurs de recherche de ne pas regarder certains fichiers, dossiers ou pages de votre site.
Blocage d’un répertoire
Par exemple, vous pouvez utiliser la règle « Interdire » pour empêcher les bots d’entrer dans la zone d’administration de votre site Web :
User-agent: *
Disallow: /admin/Cela gardera toutes les URL commençant par ‘/admin/’ à l’écart de tous les robots des moteurs de recherche.
Utilisation de caractères génériques
User-agent: *
Disallow: /*.pdf$Avec le joker ‘*’, vous pouvez bloquer tous les fichiers PDF sur votre site web. N’oubliez pas de vérifier votre fichier robots.txt après avoir apporté des modifications pour vous assurer de ne pas bloquer des parties importantes du site.
3. Autoriser la directive
« Disallow » bloque l’accès à certaines zones d’un site web, tandis que la directive « Allow » peut faire des exceptions dans ces zones bloquées. Il fonctionne avec ‘Disallow’ pour permettre l’accès à des fichiers ou des pages spécifiques même lorsqu’un répertoire entier est bloqué.
Pensez à un répertoire qui contient des images. Si vous souhaitez que Google Images voie une image spéciale dans ce répertoire, voici comment procéder :
User-agent: Googlebot-Image
Allow: /images/featured-image.jpg
User-agent: *
Disallow: /images/Dans ce cas, vous devez d’abord autoriser Googlebot-Image à accéder à ‘featured-image.jpg’. Ensuite, empêchez tous les autres robots de voir le répertoire ‘/images/’.
4. Directive du plan du site
La directive ‘Sitemap’ indique aux moteurs de recherche où trouver votre sitemap XML. Un sitemap XML est un fichier qui affiche toutes les pages clés de votre site. Cela facilite l’exploration et l’indexation de votre contenu par les moteurs de recherche.
Pour ajouter votre sitemap à votre fichier robots.txt vous pouvez facilement :
Sitemap: https://www.[yourwebsitename].com/sitemap.xmlAssurez-vous de changer ‘https://www. [votrenomsiteweb].com/sitemap.xml’ à l’URL réelle de votre sitemap. Vous pouvez soumettre votre sitemap à l’aide de Google Search Console. Mais le mettre dans votre fichier robots.txt garantit que tous les moteurs de recherche peuvent le trouver.
5. Directive de délai de crawl
La directive « Crawl-delay » contrôle la vitesse à laquelle les moteurs de recherche explorent votre site web. Son objectif principal est d’empêcher votre serveur web d’être trop occupé lorsque de nombreux robots essaient d’accéder aux pages en même temps.
Le temps de « retard de crawl » est mesuré en secondes. Par exemple, ce code indique à Bingbot d’attendre 10 secondes avant de lancer une autre requête :
User-agent: Bingbot
Crawl-delay: 10Soyez prudent lorsque vous définissez des délais d’exploration. Un délai trop long peut nuire à l’indexation et au classement de votre site Web. C’est particulièrement vrai si votre site comporte de nombreuses pages et est mis à jour régulièrement.
Note: Le robot d’exploration de Google, Googlebot, ne suit pas cette directive. Mais vous pouvez ajuster le taux d’exploration via Google Search Console pour éviter la surcharge du serveur.
Lisez aussi : Comment vérifier la propriété d’un site Web sur Google Search Console
6. Directive Noindex
La commande ‘noindex’ empêche les moteurs de recherche de stocker des pages spécifiques de votre site web. Mais maintenant, Google ne prend pas officiellement en charge cette règle.
Certains tests montrent que ‘noindex’ dans robots.txt peut toujours fonctionner. Mais ce n’est pas une bonne idée de dépendre uniquement de cette méthode. Au lieu de cela, vous pouvez utiliser des balises meta robots ou l’en-tête HTTP X-Robots-Tag, pour un meilleur contrôle de l’indexation.
Pourquoi est-ce robots.txt important pour le référencement ?
Un fichier robots.txt bien configuré est un outil puissant pour le référencement. Ce fichier affecte la façon dont Google et les autres moteurs de recherche trouvent, parcourent et enregistrent le contenu de votre site Web. À son tour, cela affecte la façon dont votre site est vu et classé.
1. Optimiser le budget de crawl
Le budget de crawl est le nombre de pages que Googlebot indexera sur votre site Web dans un certain laps de temps. Si vous optimisez bien votre budget de crawl, Google se concentrera sur votre contenu important.
Vous pouvez utiliser robots.txt pour empêcher Google de visiter des pages inutiles et de passer plus de temps sur votre précieux contenu.
2. Bloquer les pages en double et non publiques
Le contenu dupliqué est un problème courant qui peut nuire à votre référencement. Cela déroute les moteurs de recherche et affaiblit l’autorité de votre site Web.
À l’aide de robots.txt, vous pouvez bloquer l’accès aux pages dupliquées, comme les versions PDF ou le contenu plus ancien. De cette façon, les moteurs de recherche peuvent se concentrer sur les versions originales et les plus importantes de vos pages.
Lisez aussi : Qu’est-ce que le contenu dupliqué : comment le repérer et l’empêcher
3. Masquer les ressources
Masquer les fichiers CSS ou JavaScript aux moteurs de recherche peut sembler une bonne idée pour gérer le budget de crawl de votre site Web. Mais ce n’est pas le cas.
Les moteurs de recherche utilisent ces fichiers pour afficher correctement vos pages et comprendre le fonctionnement de votre site web. Si vous bloquez ces fichiers, les moteurs de recherche peuvent avoir du mal à évaluer l’expérience utilisateur de votre site Web. Cela nuit à votre classement dans les recherches.
Comment utiliser robots.txt interdire tout pour les moteurs de recherche
Vous pouvez vérifier le fichier robots.txt de votre site en ajoutant simplement « robots.txt » à la fin d’une URL. Par exemple, https://www.bluehost.com/robots.txt. Voyons comment vous pouvez configurer le fichier robots.txt à l’aide du gestionnaire de fichiers Bluehost :
1. Accéder au gestionnaire de fichiers
- Connectez-vous à votre gestionnaire de compte Bluehost.
- Naviguez jusqu’à l’onglet « Hébergement » dans le menu de gauche.
- Cliquez sur « Gestionnaire de fichiers » dans la section « Liens rapides ».

2. Localisez le fichier robots.txt
- Dans le ‘Gestionnaire de fichiers’, ouvrez le répertoire ‘public_html’, qui contient les fichiers de votre site Web.

- Recherchez le nom de fichier ‘robots.txt’ dans ce répertoire.

3. Créez le fichier robots.txt (s’il n’existe pas)
Si le fichier robots.txt n’est pas présent, vous pouvez le créer. Voici comment procéder :
- Cliquez sur le bouton « + Fichier » dans le coin supérieur gauche.
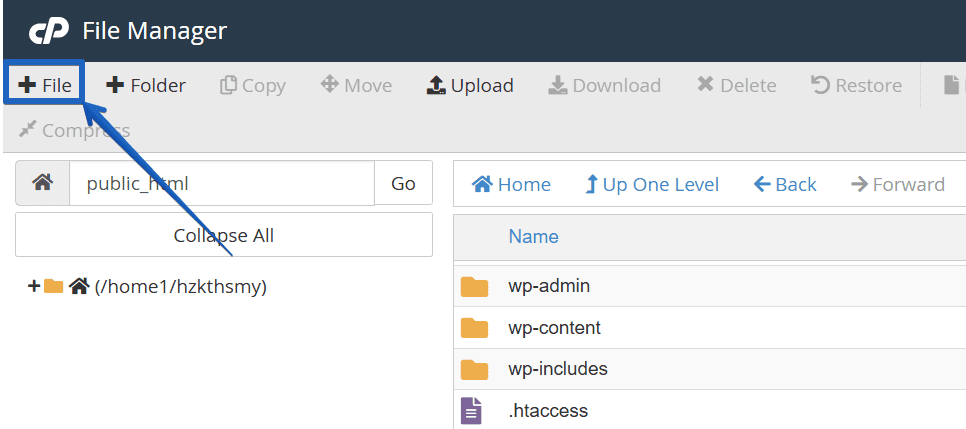
- Nommez le nouveau fichier ‘robots.txt’. Assurez-vous qu’il est placé dans le répertoire ‘/public_html’.

4. Modifiez le fichier robots.txt
- Faites un clic droit sur le fichier robots.txt et sélectionnez « Modifier ».

- Un éditeur de texte s’ouvrira, vous permettant d’ajouter ou de modifier des directives.

5. Configurez robots.txt pour interdire les moteurs de recherche
Pour contrôler la façon dont les moteurs de recherche interagissent avec votre site, vous pouvez ajouter des directives spécifiques au fichier robots.txt. Voici quelques configurations courantes :
- « Interdire à tous » les moteurs de recherche d’accéder à l’ensemble du site : Pour empêcher tous les robots des moteurs de recherche d’explorer une partie de votre site, ajoutez les lignes suivantes :
User-agent: *
Disallow: /Cela indique à tous les agents utilisateurs (indiqués par l’astérisque *) de ne pas accéder aux pages de votre site.
- Interdire à certains moteurs de recherche d’un dossier spécifique : Si vous souhaitez empêcher le bot d’un moteur de recherche particulier d’explorer un répertoire spécifique, spécifiez l’agent utilisateur du bot et le répertoire :
User-agent: Googlebot
Disallow: /example-subfolder/Cet exemple empêche le bot de Google d’accéder au répertoire /example-subfolder/.
- ‘Interdire tous’ les bots de répertoires spécifiques : Pour bloquer tous les robots de certains répertoires, listez-les comme suit :
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /junk/Cette configuration empêche tous les agents utilisateurs d’accéder aux répertoires /cgi-bin/, /tmp/ et /junk/.
Considérations importantes avant d’utiliser robots.txt Interdire tout
Il est important de savoir comment et quand vous utilisez « Interdire tout » dans votre fichier robots.txt, car cela peut sérieusement affecter le référencement de votre site. Voici quelques points à garder à l’esprit avant d’utiliser robots.txt Tout interdire.
1. Objet de robots.txt fichier
Avant de modifier votre fichier robots.txt, vous devez savoir à quoi il sert. Le fichier robots.txt n’est pas destiné à être un outil de sécurité ou à cacher votre site Web de toute menace. Si vous avez du contenu sensible, il est préférable d’utiliser des méthodes plus fortes comme la protection par mot de passe au lieu de simplement utiliser robots.txt.
2. Impact sur la présence de l’indice
L’utilisation de robots.txt interdire tout peut sérieusement affecter la façon dont votre site Web s’affiche dans les moteurs de recherche. Lorsque vous empêchez les robots des moteurs de recherche de visiter votre site, ils finiront par supprimer vos pages de leur index. En conséquence, votre trafic provenant de la recherche Google diminuera fortement.
3. Impact sur l’équité des liens
L’équité des liens (ou jus de lien) est très importante pour un bon classement dans le référencement. Lorsque des sites Web dignes de confiance sont liés à vos pages, ils partagent une partie de leur autorité. Mais si vous utilisez robots.txt Interdire tout pour bloquer les robots des moteurs de recherche, vous arrêtez également le flux de l’équité des liens.
4. Risque d’accessibilité pour le public
Robots.txt fichiers sont accessibles au public. N’importe qui peut voir quelle partie de votre site Web est restreinte aux moteurs de recherche. Pour une meilleure sécurité, utilisez l’authentification côté serveur, des pare-feu, des méthodes de blocage d’IP ou placez du contenu sensible dans des répertoires sécurisés.
5. Évitez les erreurs de syntaxe
Une petite erreur de syntaxe dans votre fichier robots.txt peut entraîner une exploration involontaire. Cela peut empêcher les moteurs de recherche d’accéder aux pages importantes ou ne pas bloquer les zones indésirables.
Pour éviter cela, vérifiez toujours votre syntaxe et votre structure avant d’apporter des modifications. Vous pouvez également utiliser un vérificateur de syntaxe en ligne ou des outils de test pour identifier les erreurs.
6. Testez robots.txt fichier
Des tests réguliers permettent de confirmer que vous ne bloquez pas par inadvertance du contenu essentiel ou que vous ne laissez pas des sections importantes de votre site sans protection. Il garantit également que votre fichier robots.txt reste un élément efficace de la stratégie de référencement de votre site Web.
A lire aussi : Comment optimiser le contenu pour le référencement sur WordPress
Réflexions finales
La maîtrise de robots.txt est une compétence clé pour les propriétaires de sites Web et les référenceurs. Lorsque vous comprenez comment cela fonctionne, vous pouvez aider les moteurs de recherche à trouver votre contenu important. Cela peut conduire à une meilleure visibilité, à un meilleur classement dans les recherches et à plus de trafic organique.
Mais utilisez robots.txt interdisez tout très soigneusement. Cela peut avoir des effets majeurs sur votre référencement à long terme. En suivant les meilleures pratiques, en vérifiant souvent votre fichier robots.txt et en vous tenant au courant des mises à jour des moteurs de recherche, vous pouvez tirer le meilleur parti de robots.txt. Cela vous aidera à optimiser votre site Web pour réussir.
Foire aux questions
« Interdire tout » dans robots.txt empêche tous les robots des moteurs de recherche d’explorer n’importe quelle partie de votre site.
Robots.txt aide les robots d’exploration à comprendre quelles pages indexer. Cela affecte votre visibilité sur la recherche Google et votre classement.
L’utilisation de robots.txt Interdire tout peut supprimer vos pages des résultats de recherche, entraînant une perte de trafic et des dommages SEO dont il faut du temps pour se remettre.
Oui, l’utilisation de « Interdire tout » peut nuire à votre référencement. Cela peut rendre votre site difficile à trouver sur Google et affecter votre visibilité dans Google Search Console.
Pour annuler la directive « Tout interdire » :
1. Supprimez « Interdire : / » du fichier robots.txt.
2. Soumettez le fichier robots.txt mis à jour dans Google Search Console.
3. Renvoyez le sitemap XML pour aider les moteurs de recherche à redécouvrir les pages plus rapidement.
4. Surveillez Google Search Console pour les erreurs d’exploration.
Non, robots.txt interdire tout n’est pas un bon moyen de protéger le contenu privé. Il est préférable d’utiliser des options de sécurité solides, comme les mots de passe, pour les informations sensibles.
Vérifiez et mettez à jour votre fichier robots.txt après avoir repensé votre site Web, déplacé du contenu ou apporté des modifications importantes à la mise en page de votre site. Assurez-vous qu’il correspond à votre stratégie de référencement actuelle et que votre sitemap XML est correctement lié.

Ecrire un commentaire