AI agents stop being useful the moment they forget what happened yesterday. A support bot that loses user preferences, a research agent that repeats the same searches or an automation worker that cannot pick up after a restart all hit the same wall: memory. Hermes Agent memory matters because it turns one-off model outputs into ongoing, stateful work that can continue across sessions, tools and channels.
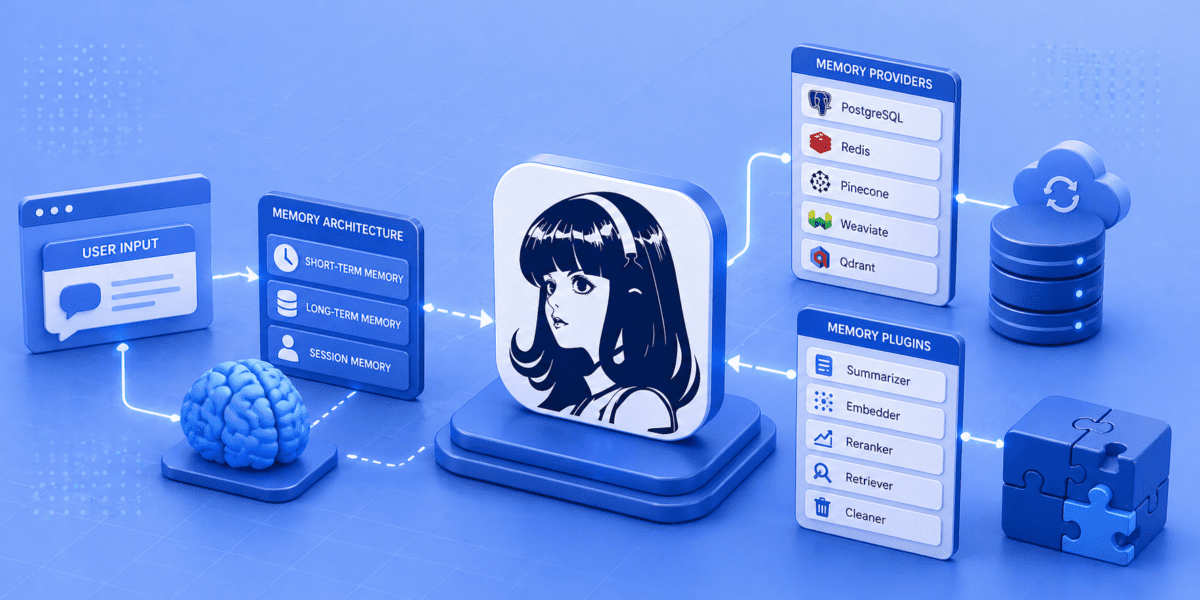
Hermes Agent is best understood as an agent-first runtime for autonomous workflows that learn over time. It gives agents a structured way to persist context through files like MEMORY.md and USER.md, while also supporting external providers such as Honcho. This makes memory flexible enough for messaging assistants, research workflows, browser automation, scheduled tasks and subagent execution.
Instead of starting from zero each time, Hermes Agent can build on prior context and support workflows that improve over time.
For developers, the real question is not whether memory exists, but how it is captured, stored, retrieved and extended without making the agent noisy or expensive. The sections below break down the memory layer itself, the runtime around it, provider options, plugin hooks, operating practices and the infrastructure choices that keep persistent agents alive for weeks instead of minutes.
What is Hermes Agent memory?
Hermes Agent memory is the persistent context layer that helps the agent remember information across sessions. Instead of treating every conversation as a fresh start, Hermes can store useful details about users, workflows, preferences, tasks and prior outputs.
At a basic level, Hermes Agent memory helps the agent answer questions like:
- Who is this user?
- What have they asked me to do before?
- What preferences should I follow?
- What projects or workflows are ongoing?
- What facts should I preserve for future sessions?
Hermes uses built-in memory files such as MEMORY.md and USER.md. MEMORY.md stores persistent agent notes, while USER.md supports user-specific context. Hermes also stores session history so prior conversations can be referenced later.
This makes Hermes Agent memory different from a simple chat history. Chat history records what happened. Memory decides what should matter later.
For example, if a user repeatedly asks an agent to research competitors, summarize findings and publish updates, the agent can gradually learn the structure of that workflow. It can remember preferred formats, recurring tools, key entities and task patterns. Over time, this turns the agent from a reactive assistant into a more useful autonomous system.
Once memory is defined, the next step is understanding why it matters for agents that run beyond a single session.
How Hermes Agent cross-session memory works?
Hermes Agent memory is designed to carry context from one session to the next. Instead of treating each conversation as a blank slate, Hermes can store useful information and retrieve it later when it becomes relevant.
At a high level, the memory flow works like this:
- A user interacts with Hermes Agent.
- The agent identifies information worth saving.
- That information is stored in persistent memory.
- Hermes summarizes longer context using an LLM.
- The memory is indexed for retrieval.
- Future sessions can search and reuse that memory.
A key part of this process is search. Hermes Agent memory can use SQLite FTS5, which is SQLite’s full-text search engine, to retrieve relevant stored memory efficiently. This helps the agent find older information without loading every past conversation into the context window.
LLM summarization is also important. Raw conversation logs can become too long and noisy. Hermes can summarize past interactions into more compact memory entries, making retrieval cleaner and reducing context bloat.
The result is a memory system that can store detailed history while still keeping future prompts focused.
Hermes Agent memory architecture explained
The Hermes Agent memory architecture can be understood in five layers:
- Capture
- Processing
- Storage
- Retrieval
- Execution.
Each layer handles a different job so the runtime can decide what to keep, how to organize it and when to inject it back into prompts or tools. Let’s understand the layers in detail:
1. Capture layer
The capture layer collects information from user interactions, agent responses, tool outputs, files, browser activity and messaging platform conversations.
Not every piece of information should become long-term memory. The system needs to distinguish between temporary context and durable knowledge. For example, a one-time instruction may not need to persist, but a user preference or recurring workflow likely should.
2. Processing layer
The processing layer decides what to do with captured information. It can summarize long exchanges, classify useful facts, remove unnecessary information and prepare content for storage.
This layer matters because raw chat logs can become messy. Without summarization and filtering, memory becomes bloated and retrieval becomes less useful.
3. Storage layer
The storage layer stores memory in built-in files, session databases or external providers.
Hermes includes built-in memory through files such as MEMORY.md and USER.md. It can also work with external memory providers. The Hermes documentation lists provider plugins including Honcho, OpenViking, Mem0, Hindsight, Holographic, RetainDB, ByteRover and Supermemory.
4. Retrieval layer
The retrieval layer brings relevant memory back into context before the agent responds.
When an external memory provider is active, Hermes can prefetch relevant memories before each turn, inject provider context into the system prompt and sync conversation turns back to the provider after the response.
5. Execution layer
The execution layer is where memory influences action. The agent uses retrieved context while calling tools, running browser tasks, delegating to subagents or responding through messaging platforms.
This is where memory becomes operational. It does not just sit in storage. It changes what the agent does next.
The three Hermes Agent memory tiers: core, archival and recall
Hermes Agent memory can be understood in three practical tiers: core memory, archival memory and recall memory.
1. Core memory
Core memory contains the most important facts the agent should always remember. This can include the user’s preferences, identity, recurring instructions, project context and important operating rules.
Examples include:
- Preferred response format
- Long-term project goals
- Important user preferences
- Agent persona rules
- Stable workflow instructions
Core memory should stay concise. It is the agent’s high-priority memory layer.
2. Archival memory
Archival memory stores larger amounts of historical information. This can include previous conversations, completed tasks, research outputs, logs and long-form notes.
Archival memory is useful because not everything belongs in core memory. Some information may not be needed every time, but should still be available when relevant.
Examples include:
- Past research summaries
- Previous task outputs
- Historical user requests
- Project notes
- Long-running workflow records
Archival memory gives Hermes Agent depth without overloading the active context.
3. Recall memory
Recall memory is the layer that retrieves useful information when needed. When a user asks a question or starts a task, Hermes can search stored memory and bring relevant context back into the conversation.
This is where FTS5 and summarization become useful. Instead of relying only on recent chat history, Hermes can search across persistent memory and recall what matters.
In simple terms:
Recall memory helps the agent find the right information at the right time.
Core memory tells the agent what it should always know.
Archival memory stores what the agent may need later.
How the memory system works over time?
The Hermes Agent memory system follows a lifecycle, not a single write operation. Good agents do not save everything. They decide what is worth keeping, compress what is too large and retire what stops being useful.
The lifecycle usually looks like this:
- An interaction or tool event happens: A user message, browser result, file change or subagent output enters the runtime.
- The agent evaluates memory value: The runtime checks whether the event has long-term importance, short-term relevance or no future value.
- Memory is written or summarized: Important items are saved directly or condensed into a smaller durable form.
- Indexes are updated: Searchable metadata, vector embeddings or lookup keys are refreshed for later retrieval.
- Relevant context is retrieved later: When the next task starts, the runtime pulls only the memory that fits the current goal.
- Low-value items are archived or evicted: Old logs, duplicated notes and stale context are compressed, moved or dropped.
Agents stay more accurate when the lifecycle includes pruning. Without it, even good retrieval models start surfacing clutter instead of signal.
Who should use Hermes Agent memory?
Hermes Agent memory is useful for developers and teams building agents that need continuity across more than one task or conversation.
It is especially useful for:
- Developers building long-running AI agents
- Teams creating messaging assistants for Slack, Discord, Telegram or email
- Automation builders running browser, research or scheduled workflows
- AI teams that need user-specific context across sessions
- Operators managing agents that coordinate tools, files and subagents
If an agent only answers isolated prompts, basic chat context may be enough. But if it needs to remember users, projects, preferences, prior outputs or recurring workflows, Hermes Agent memory becomes a core part of the system design.
After the lifecycle is clear, the next decision is where memory should live.
Hermes Agent memory providers
Hermes Agent memory providers can follow different storage and retrieval patterns depending on what your agent needs most: transparency, speed, scale or relationship awareness. No single backend fits every workload.
Most provider choices fall into a few practical categories:
- File-based memory: Good for inspectable long-term notes, lightweight setups and version-controlled knowledge
- Vector databases: Best when semantic search across large memory sets matters most
- Relational databases: Useful for structured entities, metadata and SQL-based querying
- Graph databases: Helpful when relationships between people, tasks and concepts drive retrieval quality
- Redis-style cache memory: Fast for short-term state, recent activity and ephemeral coordination
- External memory platforms: Worth considering when you want a dedicated memory layer outside the core runtime
The choice often depends on whether your agent needs inspectable files, semantic recall or high-speed operational state. Many production systems mix two or more approaches instead of betting on one.
The matrix below shows where common options fit.
| Provider | Best fit | Main strength | Tradeoff |
|---|---|---|---|
| Honcho | Agent memory and user-context workflows | Externalized memory layer with user-aware retrieval patterns | Needs careful production evaluation and provider coordination |
| Pinecone | Vector search at scale | Fast semantic retrieval across large memory sets | Less human-readable than file-based approaches |
| Redis | Short-term memory and cache | Very fast reads and writes | Not ideal as the only long-term memory layer |
| Neo4j | Relationship-heavy memory | Strong graph traversal for linked facts and entities | More modeling work up front |
| pgvector | SQL plus vector search in PostgreSQL | Structured data and embeddings in one stack | May need tuning as memory volume grows |
The right provider depends on the use case. A solo developer may start with built-in memory. A production assistant with many users may need a provider that supports user modeling, retrieval and observability.
For teams that need deeper user modeling, Honcho is one provider worth understanding.
How Honcho can fit into Hermes Agent memory?
Honcho Hermes Agent memory is one of the most important provider angles to cover because Honcho is documented as an official Hermes memory provider.
The Hermes docs describe Honcho as an AI-native memory backend that adds dialectic reasoning and deep user modeling on top of Hermes built-in memory system. It maintains a running model of the user, including preferences, communication style, goals and patterns.
Honcho’s own documentation says it gives Hermes persistent cross-session memory and user modeling. It also describes Hermes Agent as an open-source AI agent with tool-calling, terminal access, a skills system and multi-platform deployment across channels such as Telegram, Discord, Slack and WhatsApp.
A simple pseudo-configuration might look like this:
A realistic configuration pattern may look like this:
memory:
provider: honcho
honcho:
api_key: ${HONCHO_API_KEY}
project_id: hermes-production-agentThe exact configuration should follow current Hermes and Honcho documentation, but this shows the general idea: Honcho becomes the provider layer while Hermes continues using its built-in memory.
Honcho is useful when the agent needs deeper user awareness. For example, a personal assistant, team operations agent or research assistant may need to remember goals, preferences and recurring patterns across multiple conversations.
Providers decide where memory lives, while plugins help shape how memory behaves.
Hermes Agent memory plugins
Hermes Agent memory plugins let developers change memory behavior without rewriting the whole runtime. That matters when you need custom filtering, domain-specific ranking or downstream sync jobs tied to memory events.
A plugin system can support lifecycle hooks such as:
| Hook | What it does | Example |
|---|---|---|
| Pre-write | Cleans or classifies memory before storage | Remove sensitive data before saving |
| Post-write | Indexes or syncs memory after storage | Push new memory to a provider |
| Pre-retrieve | Filters or ranks memory before use | Prioritize project-specific context |
| Post-retrieve | Compresses or formats retrieved context | Summarize memory before prompt injection |
The Hermes provider system already supports provider-specific tools that let the agent search, store and manage memories.
Extensibility can go further than hooks. Custom skill directories and third-party skills give teams room to add domain actions that generate memory in a controlled way. Root access also makes it possible to modify system-level configuration when a plugin needs packages, local services or special file paths.
Plugins are most effective when each hook has a narrow purpose. Small, well-observed hooks are easier to debug than one large plugin that touches every stage.
Once memory is running, the main goal is keeping it useful, accurate and manageable.
Memory management best practices
Hermes Agent memory management is mostly about signal control. If everything gets saved and nothing gets reviewed, recall quality drops, costs rise and prompts fill with low-value context.
Teams usually get better results when they follow a few operating rules from day one:
1. Separate memory by type
Keep user preferences, task history, project details, tool outputs and system notes separate where possible.
2. Summarize long histories
Agents do not need every word from every session. They need durable insights that improve future responses.
3. Monitor retrieval quality
Check whether the agent is pulling relevant memories into context. If not, improve filtering, tagging or provider tuning.
4. Use eviction rules
Some memory should expire. Remove temporary project details, outdated instructions and low-value logs when they stop being useful.
5. Back up critical files
Treat MEMORY.md, USER.md, skills, logs and provider configuration as production assets.
6. Balance memory value with cost
External memory providers can improve retrieval and user modeling, but they can also add operational overhead. A hybrid setup can work well: built-in memory for core persistence and external providers for richer retrieval.
Tip: Create one retention policy for short-term operational state and another for durable knowledge. Mixing those horizons is a common reason agents either forget too much or remember too much.
Good memory operations are less about one perfect database and more about disciplined boundaries between what is temporary, what is durable and what should never be stored at all.
Hermes Agent memory vs LangChain memory
Both approaches deal with context, but they are framed differently. Hermes centers memory inside an agent-first runtime, while LangChain memory is often used as a framework-level abstraction inside larger chains, graphs or application pipelines.
A side-by-side view helps clarify the difference.
| Area | Hermes Agent memory | LangChain memory |
|---|---|---|
| Primary use case | Persistent memory inside an agent-first runtime | Memory abstraction inside chains, graphs and custom LLM apps |
| Memory framing | Built around long-running agents that operate across sessions | Built around developer-defined workflows and orchestration patterns |
| Persistence | Designed for cross-session memory and long-term agent context | Depends on the storage backend and how the developer configures it |
| Retrieval | Focuses on recalling useful agent context during future sessions | Can support retrieval through integrations, retrievers and memory modules |
| Customization | Supports agent-specific memory behavior, providers and plugins | Highly flexible, but requires more manual setup and orchestration |
| Best fit | Always-on agents, autonomous workflows and messaging-based assistants | Custom LLM applications, RAG pipelines and agentic app frameworks |
| Infrastructure needs | Benefits from persistent runtime, stable storage and VPS deployment | Depends on the app architecture and deployment setup |
Common Hermes Agent memory challenges and fixes
Neither approach is automatically better. The right choice depends on whether you want a runtime built around persistent agency or a toolkit for assembling your own orchestration patterns.
| Challenge | What happens | Fix |
|---|---|---|
| Memory becomes noisy | The agent stores too much low-value or outdated information. | Add summarization, filtering and cleanup rules. |
| Retrieval gets slower | Memory grows beyond simple lookup and takes longer to search. | Use faster storage, indexing or a dedicated memory provider. |
| Context becomes too large | Too much retrieved memory enters the prompt. | Rank, compress or summarize retrieved context before injection. |
| Local setup fails | The agent stops when the local machine goes offline. | Move the runtime and memory to a persistent VPS. |
| Docker memory gets lost | Memory is stored inside the container instead of a persistent volume. | Configure Docker volumes for memory, sessions and agent data. |
| Provider costs grow | External memory calls increase as usage scales. | Use a hybrid setup with built-in memory plus provider-backed retrieval. |
| Plugins conflict | Multiple plugins modify the same memory flow. | Define clear lifecycle hooks and test plugins separately. |
| Backups are missing | Memory cannot be recovered after deletion or misconfiguration. | Schedule regular backups and test restore steps. |
Memory-heavy agents need more than good software design. They also need dependable infrastructure.
Infrastructure requirements for memory-heavy agents
Hermes Agent memory needs stable infrastructure because long-running agents are not burst workloads. They stay active, write logs, retrieve memory, run tools and respond across channels.
Key infrastructure requirements include:
- NVMe SSD storage for memory, logs and execution artifacts
- Sufficient RAM for indexing and parallel execution
- Dedicated CPU resources for consistent performance
- Root access for custom providers and plugins
- Reliable uptime for messaging assistants
- Backups and snapshots for recovery
- Vertical scaling as memory grows
This is why a VPS can be a practical deployment environment for Hermes Agent. It keeps memory and runtime independent from a local machine. It also gives developers control over files, providers, skills and execution backends.
Why run agent memory on Bluehost VPS?
Running Hermes Agent locally may be enough for testing, but memory-based workflows need infrastructure that can stay available beyond a single device or session. With Bluehost VPS, Hermes Agent can keep running 24/7 while storing memory files, logs, skills and configuration on persistent NVMe storage.
Bluehost VPS is useful for Hermes Agent because it supports:
1. Always-on agent runtime
Keep Hermes Agent available even when your laptop is offline or a local session ends.
2. Persistent memory storage
Store MEMORY.md, USER.md, logs, skills and configuration in a stable server environment.
3. Full root control
Customize providers, plugins, execution settings and memory behavior based on your workflow.
4. Dedicated VPS resources
Run memory-heavy agent tasks with isolated compute, storage and bandwidth.
5. Simple Hermes access
Bluehost provides one-click Hermes Agent access, helping developers move faster from setup to production workflows.
6. Scalable infrastructure
Upgrade vertically as your agent workload, memory size and automation needs grow.
Also read: Deploy Hermes Agent on Bluehost VPS for AI Workflows
For developers moving from experimentation to production, Bluehost VPS gives Hermes Agent the reliable foundation it needs to run continuously, preserve memory and support long-term autonomous workflows.
Build persistent agent workflows with Hermes Agent
Useful agents are not defined by clever prompts alone. They become dependable when memory works as a living system, with clear architecture, the right provider choices and plugin hooks that shape how knowledge is stored and recalled.
That is what makes Hermes Agent memory important for production workflows. It gives long-running agents the continuity to remember context, learn from past interactions and improve over time.
For serious deployments, start by mapping your memory layers, choosing the right provider mix and running the stack on infrastructure built for persistence. Get started with Hermes Agent on Bluehost VPS today and build agents that keep working, learning and remembering.
FAQs
It is the persistent context layer that helps Hermes remember users, tasks and workflows across sessions. Instead of losing state after one run, the agent can carry forward useful knowledge into future actions.
LangChain memory is often used as a framework-level abstraction inside app workflows. Hermes ties memory more closely to an agent-first runtime, where persistent files, providers and runtime state support long-running behavior.
Common options include file-based memory, vector databases, relational databases, graph stores, Redis-style cache layers and external providers. The right choice depends on whether you need human-readable notes, semantic recall, relationship modeling or fast short-term state.
Honcho can act as an external provider layer for user-aware memory and retrieval workflows. Teams usually evaluate it when they want centralized memory behavior across agents or stronger identity-based recall patterns.
Yes. Plugin hooks can run before writes, after writes, before retrieval and after retrieval. Those hooks let you classify memory, trigger indexing, filter results or format context before it reaches the model.
Persistent agents need stable storage, reliable uptime, root access and scalable resources. A VPS gives you a dedicated environment where memory files, indexes, plugins and execution artifacts can keep running without depending on a local machine.

Write A Comment